由于精度有限,浮点数不能在计算机中精确表示,这个问题甚至有一个网站:
https://0.30000000000000004.com/
数字的二进制表示,在计算机课程中是基础,借此简单回顾总结下计算机中的数字表示,包括整数和浮点数
整数的二进制
base 为k的k进制的十进制表示为:
N = (an-1an-2…a1a0)k = an-1 × kn-1 + an-2 × kn-2 + … + a1 × k1 + a0 × k0
N 是一个十进制的数值且0 <= ai < k
11为10进制时:
(11)10 = 1 x 101 + 1 x 100
11为二进制时:
(11)2 = 1 x 21 + 1 x 20
base在这里是一个隐含的意义,所以在计算机中经常通过增加前缀来表示这个信息:
0x11 十六进制
0o11 八进制
0b11 二进制
对一个整数可以通过取余除以base直到为0转换为k进制,比如10转化为二进制:
| 商 | 余数 |
|---|---|
| 10 ÷ 2 = 5 | 0 |
| 5 ÷ 2 = 2 | 1 |
| 2 ÷ 2 = 1 | 0 |
| 1 ÷ 2 = 0 | 1 |
从上表可以看出,每次将商用2进行除法运算,得到商和余数。高位在下,低位在上,从下往上即可得到十进制数10的二进制表示为 1010。
负整数的二进制
计算机是按byte来进行寻址的,一个字节是8bit,int8, int16, int32, int64等它们都是2的n次方
这里以int8为例,上边已经求出了+10的二进制为 1010,在int8中为:
0000 1010
那负数呢,需要抽出一位来表示正负,也就是最高位,并且0为正,1为负,所以-10表示为:
1000 1010
这就是负数的原码,但是计算机并没有直接存储原码,如果尝试在c++中通过如下代码打印:
1 | //__int8 在windows中定义为char |
得到的并不是-10
为什么符号位1表示负,而不是0表示负?
原码、反码、补码
注意:原码、反码、补码的概念只对负数有实际意义,对于正数,原码、反码、补码都是一样的
不会有下边的操作,但也可以理解为,计算机中只有补码,只是正数的补码是它自身
负数在计算机中使用补码表示,要求补码,先了解下反码。
反码被定义为原码除符号位外其它按位取反
补码求值方法为反码+1(注意这不是补码的定义),-10的补码为:
对于-10:
原码: 1000 1010
反码: 1111 0101
补码: 1111 0110
通过代码,这次打印出了-10
1 | __int8 b = 0b11110110; |
对一个负数,如果得到它的二进制原码,可以通过如下方式快速求得补码(-0不适用,因为-0取反+1有溢出):
从右到左(低位到高)遇到第一个1不变,把1之后除符号位外的数字全部取反
如果是正数的原码,求对应负数的补码,把负号位一起取反
而补码得到原码的话也是一模一样(-$2^n$不适用,它没有原码):
从右到左(低位到高)遇到第一个1不变,把1之后除符号位外的数字全部取反
所以对于__int8 b = 0b10001010; 它是补码的话,可以得到其原码为: 11110110,即
-(2^6 + 2^5 + 2^4 + 2^2 + 2^1) = -(64 + 32 + 16 + 4 + 2) = -118
| 负数 | 原码 | 反码 | 补码 |
|---|---|---|---|
| -10 | 1000 1010 | 1111 0101 | 1111 0110 |
| -118 | 1111 0110 | 1000 1001 | 1000 1010 |
| -64 | 1100 0000 | 1011 1111 | 1100 0000 |
有意思的是-64的补码和原码是一样的!
补码的作用
- 统一+0、-0表示
如果只用原码,+0 = 0000 0000, -0 = 1000 0000,有2种不同的表示法
如果用补码表示:
+0 = 0000 0000,-0 = 1111 1111 + 1 = 0000 0000 (溢出了) - 减法可以表示为加法
a-b = a + (-b),但是如果用原码运算会得到如下情况,比如 1 + (-1):
0000 0001 + 1000 0001 = 1000 0010 = -2???
思考,这于这个加法,如果用反码怎么求?
所以对于负数,得使用专门的减法逻辑,补码解决了这个问题:
0000 0001 + 1111 1111 = 0000 0000 = 0
所以这个原理是什么?补码的本质是什么?
模和同余的思想
对于长度为n的数组,如果使下标不越界?我们会取余 i % n 使得它位于0 到 n-1之间,即
1 % n == (n+1) % n,这里n称为模,表示这个数组的容量对于时钟(12小时制),现在指针在6点,再过多久指针会停留在12点?我们可以往前拨6个小时,也可以往后拨动6个小时,即6-6 % 12 = 6+6 % 12,即往前往后的效果是一样的。时钟的0=12点,它们刚好相差一个模的大小。看上面的公式,6-6 % 12 = 6+6 % 12,
6-4 % 12 = 6+8 % 12。
即减去一个数,等价于加上一个数,这2个数相加可以整除模,这样就把减法转化成了加法,这样其实不需要引入负数,也不需要特别的符号位,只要在所有位上直接做加法运算,溢出的位舍去就行了。
以8bit数为例,计算12-10 = 2,计算机不能直接计算-10,从上边可以知道-10可以变成加上一个数,使得12-10和12+x同余,对于个8位的数,其模为28 = 256,x = 256 - 10 = 246,把246转化为二进制为:1111 0110,做加法舍去溢出后,结果是一样的,如下表格对比:
| 减法 | 加法 |
|---|---|
| 0000 1100 | 0000 1100 |
| 0000 1010(10) | 1111 0110(246) |
| 0000 0010 | 0000 0010 |
可以发现,1111 0110正是-10的补码。对于一个8位的数,可得:
原码+反码+1 = 1111 1111 + 1 = 1 0000 0000 = 256 刚好是8位的模,补码=反码+1
最大整数和最小整数
为什么8位有符号整个的范围是-128
127?而不是-127127?
limits.h中定义了整数的表示范围
1 |
对于无符号数,最小为全0,最大为全1;对于有符号整个,符号位占用一位,同样以8位为例
| 最小值 | 最大值 | |
|---|---|---|
| 无符号 | 0000 0000 | 1111 1111 |
| 十进制 | 0 | 255 |
| 有符号 | 1000 0000 | 0111 1111 |
| 十进制 | -128 | 127 |
如果用原码表示,负数的最大值为1111 1111 = -127,-128无法表示。-127到127之间共255个数,但是模有256个数,多的这个数即-0,1000 0000,在补码里为-128,在无符号数里是128
-128 = -127 - 1
即补码相加:
1000 0001 + 1111 1111 = 1000 0000
大端(big endian)和小端(little endian)
分为机器的大小端和网络字节顺序的大小端,原理相似
高位和低位,高地址和低地址
对于一个数,权重高的为高位,权重低的为低位,如16位整数0xABCDEF,AB为高位,CD为低位;对于内存地址,地址大的是高地址,地址小的为低地址,即有ph = pl + offset。
| 内存地址 | big endian | little endian |
|---|---|---|
| 0x0000 | AB | EF |
| 0x0001 | CD | CD |
| 0x0002 | EF | AB |
如何验证机器是大端还是小端?
c++:
1 | int a = 1; |
python
1 | import sys |
或
1 | import array |
网络字节顺序
网络字节顺序NBO(Network Byte Order):网络字节顺序规定在传输数据时,先传输高位字节,后传输低位字节,即“大端字节序”(Big-Endian)。比如传输0xABCD,先传输AB,再传输CD。
一般intel机器都小端,发送数据时,需要将本地字节顺序转换网络字节顺序,接收时,再将网络字节顺序转换为本地字节顺序。
浮点数表示
浮点数用于在计算机中表示小数,资料也非常多了,浮点数是一种科学计数法,即
N = m * basee
- m 称为有效数,它表示了数值的精度,1 <= m < base
- base 为进制
- e 称为指数,决定了数值的大小
对于10进制数123用科学计算法可以表示为:
123 = 1.23 * 102
计算机中浮点数的标准为IEEE754,是各大编程语言和硬件使用的标准
F = (-1)s m 2e
s是符号位,m是尾数,e是指数位,base固定为2,所以浮点数的表示只需要约定这三位即可。符号位是固定1位
定点数
在说浮点数之前,先了解一下定点数,定点数指约定小数点的位置。比如在8位里,可以约定第1位表示符号,3位表示整数,最后4位表示表示小数位。一个数可以拆分成整数+小数。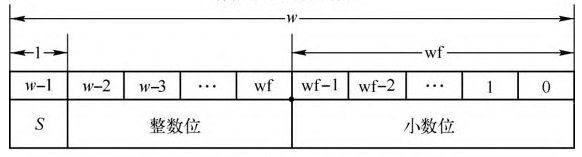
在原码表示法中
将小数转为二进制使用乘base取整法,比如将0.125转为二进制: 0.001 (1x2-3)
| 积 | 整数位 |
|---|---|
| 0.125*2=0.25 | 0 |
| 0.25*2 = 0.5 | 0 |
| 0.5*2 = 1.0 | 1 |
一些数的原码表示: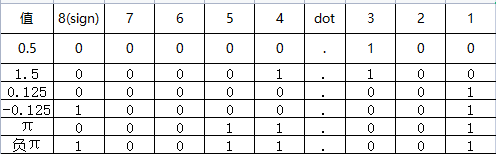
可见,在8位定点数中,$\pi$ = 3.14159 因为精度问题无法准确表示,只能近似表示为3.125,因为小数位无法表示所有的实数,实数是连续的,但是二进制表示不是连续的。
- 整数位越大,数值范围越大,但是精度越低;小数位越大,精度越高,但是范围越小。这点在浮点数也有类似的规律
- 每一个小数,其实都有一个等效的整数。比如1.5 等效整数为 12, 即$1.5*2^3$,3即为小数位数。在不考虑小数点位置情况下,1.100 << 3 = 1100(B) = 12(D)
通过$x * 2^n$,n为小数位数,可以快速求得x的等效数
单精度浮点数
单精度用32位(4字节)表示,最高位为符号位,e 为8 bits,m 为23 bits,如下: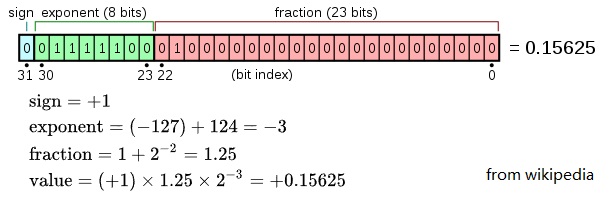
0.15625的浮点数怎么来的?
转化为定点二进制:0.15625 * 25 = 5.0 = 0.00101 = 1.01 x 2-3
符号位 0,e = -3, m = 1.01,因为规范化(normal number)之后,m的首位总是1,所以作为约定可以舍去,尾数其实比实际的多 1 位,也就是说单精度的尾数是 24 位。这样尾数部分是01
指数有正、有负,并没有直接用补码表示。为避免使用符号位,用移码来表示。以e=8为例,它的取值范围为0~255,IEEE 754规定,e的真实值必须再减去一个中间数,对于8位的E,这个中间数是127,x - 127 = -3, 则x=124=01111100,这个为指数部分。
对于n位的指数来说,阶码:2e-1 - 1 为0
所以整个内存表示是:0 01111100 01000000000000000000000,可以通过下边程序验证
1 | float f = 0.15625f; |
为什么不使用补码?补码有什么问题?
移码通过加上一个固定的偏移,去掉符号位,相对大小不变,更利于比较大小,便于对阶,即把较小的阶对齐较大的阶,方便加法运算
-1 补码 = 1 111 1111
1 补码 = 0 000 0001
-1 < 1 但是按位比较 1 111 1111 > 0 000 0001,结果不对
-1 移码 = 0 111 1111
1 移码 = 1 000 0001
比较结果正确
移码快速计算:补码+2n-1,即最高符号位取反
值得注意的,浮点数阶码中使用的偏置是2n-1 - 1而不是*2n-1*。在8位中是127而不是128,11位的双精度浮点数中是1023而不是1024。所以有:
- 阶码(E)= [真值(e)]补+ 2n-1 - 1 = [真值]移 - 1
- [真值(e)]补 = [阶码 + 1]移 => 真值(e)= [真值(e)]补补
想了一下阶码127问题,偏移为128时候也能表示数没有问题。但是范围和对称性和127不一样;可以结合非规格化数理解。
双精度浮点数
双精度浮点数用64位(8字节)表示,最高位为符号位,e 为 11 bits,m 为 52 bits,如下:
由Fresheneesz,CC BY-SA 3.0
表示方法和逻辑一致,不再赘述
一些浮点数的问题
阶码范围
阶码因为要表示负数,只有7位有效位,范围是0~127,所以偏移取127,
8位数范围应该在1~254范围,则阶码范围在-126~127之间
阶码有二类特殊情况:
- 全为0,此时阶码最小
- 当尾数m全为0时表示0,根据符号位会有+0和-0两种表示法,但都是0。注意如果按规格化数计算 1.0 x 2-127,这个值不应该为0
- 当尾数m不全为0时,这时用来表示非规格化浮点数, 且规定阶码为 0 - 127 + 1 = -126,这样能与规格化浮点数连续。非规格化浮点数更靠近0且更密
当阶码全是 0,尾数部分不全为 0,尾数部分没有省略的前导 1,同时指数部分的偏移值比规范形式的偏移值小 1,即单精度是 -126,双精度是 -2046。这种形式的浮点数叫非规范化浮点数(denormal number)。
- 全为1,此时阶码最大,e真值为128,超出127,表示无穷
- 当尾数m全为0时,表示无穷,根据符号位会有+infinity和-infinity两种表示法
- 当尾数m不全为0时,即至少有一个1时,表示NaN
浮点数的特殊值
float.h中的定义:
1 |
以32位为例:
+0:0 00000000 0000 0000 0000 0000 0000 000
-0:1 00000000 0000 0000 0000 0000 0000 000
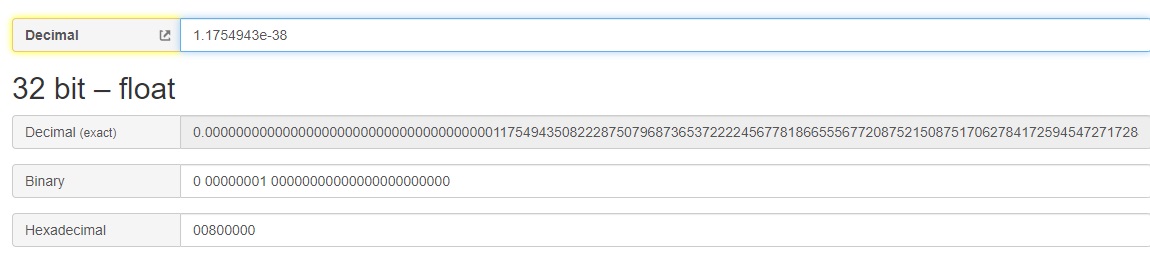
以非规格化数视角来看 0.0 x 2-126 = 0规格化最小正数:0 00000001 0000 0000 0000 0000 0000 000
阶码为1,真值为1-127=-126,+(1.0)×2−126 = 1.1754943508222875e-38
- 规格化最大正数:0 11111110 1111 1111 1111 1111 1111 111
阶码为254,真值为254-127=127,+(1+x)×2127,其中
$$
x=2^{-1} + 2^{-2} … + 2^{-23} = \frac {1+2+4…2^{22}}{2^{23}} = \frac {2^{23}-1} {2^{23}} = 1-2^{-23}
$$
最终结果为:2127*(224-1)/223 = 3.4028234663852886e+38
非规格化最小数(FLT_TRUE_MIN):0 00000000 0000 0000 0000 0000 0000 001
非规格化的阶码真值为-126
$2^{-126}\times2^{-23} = 1.401298464324817e-45$,这个数比规格化的更小,更靠近0非规格化最大值:0 00000000 1111 1111 1111 1111 1111 111
$2^{-126}\times(1-2^{-23}) = 1.1754942106924411e-38$,与规格化的最小值保持连续!!
非规格化浮点数都 |x| <<< 1,更靠近0
- 负数将符号位取反即可,是对称的,最大负数:-1.1754943508222875e-38,最小负数:-4028234663852886e+38
为什么FLT_MIN=1.175494351e-38F,小数点后为9位?
因为FLT_MANT_DIG=23+1, 224 - 1 = 16777215(10进制),有效位最多为8位。
验证 1.1754943e-38和1.1754944e-38的二进制表示和FLT_MIN是一样的
FLT_MIN这个值已经超过FLOAT的最小精度了
- EPSILON
EPSILON 表示浮点数可表示的大于1的最小数与1差值。对32位数来说:
0 01111111 0000 0000 0000 0000 0000 001,即$2^0\times(1+2^{-23}) = 2^{-23} = 1.1920928955078125e-7$
- 符点数在实数轴上并不是均匀分布的,越靠近0越密,越往Infinity越稀,比如
0 11111110 11111111111111111111111 - 0 11111110 11111111111111111111110 = 2.028240960365167e+31!
3.4028234663852886e+38 - 1 === 3.4028234663852886e+38
思考:64位浮点数的范围和精度是多少?
浮点数有小端、大端区分吗
这个问题可转化为,在计算机内存中,低地址先存放的是尾数部分,还是符号和指数部分?
显然还是需要区分的,前面打印0.15625的二进制表示,过程是从最高位到最低打印,得到:0 01111100 01000000000000000000000。可知高地址存的是符号和指数,低地址存的是尾数。
1 | //在小端机器上,按内存地址从低到高打印浮点数 |
网络传输时,可以把浮点数当成一个等效的整数(即内存表示一样的整数)进行大小端转换。
0.1 + 0.2 = 0.30000000000000004
总结原因有2点:
0.1和0.2 在二进制中无法精确表示,尾数部分会在0011上循环
0.1:0 01111011 10011001100110011001101:0.10000000149011611938476562
0.2:0 01111100 10011001100110011001101:0.20000000298023223876953125
和为
0.30000000447034836符点数加法对进行对阶操作,会使尾数右移。进一步损失精度
1 | printf("0.1 + 0.2= %.17lf\n", 0.1 + 0.2); //0.30000000000000004 |
注意这里不同精度下计算结果不一样,且与直接用十进制值验证的结果也不一样。说明运算过程中是有精度损失的。
0.30000000000000004这个是在双精度浮点数中相加才会出现的结果。
0.1+0.2双精度浮点数相加动手验证一下
0.1:0 01111111011 1.1001100110011001100110011001100110011001100110011010
0.2:0 01111111100 1.1001100110011001100110011001100110011001100110011010
0.1 指数为1019,0.2为1020,需要对阶,0.1指数变为1020,尾数右移一位:
0.1:0 01111111100 0.1100110011001100110011001100110011001100110011001101
0.2:0 01111111100 1.1001100110011001100110011001100110011001100110011010
0.3:0 01111111100 10.0110011001100110011001100110011001100110011001100111
10.0110011001100110011001100110011001100110011001100111 * 21020-1023 = 0b100110011001100110011001100110011001100110011001100111 * 2-3-52
1 | 0b100110011001100110011001100110011001100110011001100111 * 2 **(-3-52) |
[IEEE 754] https://babbage.cs.qc.cuny.edu/IEEE-754.old/IEEE-754references.html
[wiki] https://zh.wikipedia.org/wiki/%E6%B5%AE%E7%82%B9%E6%95%B0
baseconvert